Attention笔记
attention机制简单来说就是计算当前上一步得到的hidden与output_encoder的相关性。
传统Attention计算步骤
分为以下几个步骤:
- 计算当前步$S_{i-1}$与输入$h_j$中每一个 token 表示
encoder_output的相关性$e_{i,j}$(矩阵乘法,nn.Linear) 计算当前步–生成第i个词语与第j个输入$h_j$的权重$a_{i,j}$(将归一化):$a_{i,j}=\frac{exp(e_{i,j})}{\sum_{k=1}^Texp(e_{i,k})}$
计算当前词的上下文向量$C_i=\sum_{j=1}^{T_x}a_{ij}·h_j$
- $S_i=f(S_{i-1},y_{i-1},C_i)$, $S_i$是 hidden state of rnn
- $P(y_i | y_1,…,y_{i-1},x)=g(y_{i-1},S_i,C_i)$
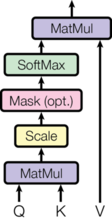
Attention抽象理解
Q,K,V三个矩阵,Query、Key、Value, Q 去 K 进行查询,使用查询到的结果即权重,去乘以 V ,归一化后得到最后的表示,即
$Softmax(\frac{Q x K^T}{\sqrt d_k})·V=Z$
个人理解,当 Q = V时,K=encoder_output 的时候,为常见的 Attention Mechanism ,当 Q = V = K 时,为 self-Attention